項目反応理論に基づく尺度開発の実践
この記事は、Stan Advent Calendar 2020 の25日目の記事です。
この記事では、これまでの記事の内容のうち、7日目の項目反応理論の記事を参考に尺度開発を行います。また、項目反応理論に基づき推定した特性値θについて、6日目のt検定の記事を参考に性差を検討します。統計は初心者なので、誤りなどがあればぜひコメントいただけると嬉しいです。stanに関する部分にのみ興味がある方は、前半を読み飛ばしていただくとスムーズかと思います。
データの概要
今回使用するデータは、2017年~2018年に日本の小中学生1962名を対象に実施された質問紙(5件法)の調査データです。
| 番号 | 時期 | 都道府県 | 学校種 | 協力者数 | 欠損を除いた協力者数 |
|---|---|---|---|---|---|
| 1 | 2017年6月 | 東京都 | 公立小学校 | 214 | 204 |
| 2 | 2017年9月 | 兵庫県 | 公立中学校 | 580 | 555 |
| 3 | 2017年9月 | 兵庫県 | 公立中学校 | 549 | 527 |
| 4 | 2017年9月 | 熊本県 | 公立小学校 | 211 | 202 |
| 5 | 2017年10月 | 広島県 | 公立中学校 | 91 | 91 |
| 6 | 2017年10月 | 広島県 | 公立中学校 | 25 | 25 |
| 7 | 2017年10月 | 広島県 | 公立中学校 | 75 | 75 |
| 8 | 2018年10月 | 広島県 | 公立小学校 | 49 | 49 |
| 9 | 2018年12月 | 鹿児島県 | 公立小学校 | 168 | 147 |
| 合計 | 小4校+中5校 | 1962 | 1875 |
この質問紙調査では、新たに「理科における認知欲求尺度(NCSE:Need for Cognition Scale in Science Education)」を開発することを意図していました。認知欲求(NC: Need for Cognition)とは、「努力を要する認知活動に従事したり,それを楽しむ内発的な傾向」と定義されています(Cacioppo & Petty, 1982; Cacioppo, Petty, Feinstein, Blair, & Jarvis, 1996)。簡単に言えば、「考えるって楽しい!」と思うかどうかの個人の傾向です。認知欲求尺度は日本語成人版(神山・藤原, 1991)も開発されていますが、子供を対象とした日本語版の尺度や特定の教科の学習内容に特化した尺度は開発されてきませんでした。
そこで、この研究では理科の学習に特化した認知欲求を測定できる尺度を開発することにしました。つまり、「科学的に考えるのって楽しい!」と思うかどうかの個人の傾向を測る尺度を作成しようという試みです。質問項目は15項目が作成され、スクリーニングを通して、最終的には14項目が残りました。
| Q | 質問項目 | |
|---|---|---|
| 1 | 理科の知識を使って,自然現象を説明していくことは楽しい。 | |
| 2 | 実験結果について考察する時間が好きである。 | |
| 3 | 自分の考えが合っていたかどうかを実験で確かめることが好きである。 | |
| 4 | 理科の知識を日常生活につなげるようにしている。 | |
| |
|
|
| 6 | 自分の考えを確かめていく過程は楽しい。 | |
| 7 | 身の回りの自然現象に対して疑問を持つ方だ。 | |
| 8 | ふしぎな自然現象に対して説明を考えていくことが好きだ。 | |
| 9 | 問題を追究していく過程を楽しむことができる。 | |
| 10 | 自分の考えをもとに計画していく実験は楽しい。 | |
| 11 | 実験は,予想・仮説をしっかりと考えてから取り組みたい。 | |
| 12 | ふしぎな自然現象に出会うとワクワクする。 | |
| 13 | 自然現象のきまりを考えることが好きである。 | |
| 14 | 予想・仮説を確かめる方法について考えることは楽しい。 | |
| 15 | 自然現象に対して自分なりの説明ができると満足を感じる。 |
1:まったくあてはまらない 、2:あまりあてはまらない、3:どちらともいえない 、4:ややあてはまる 、5:とてもよくあてはまる
また、調査ではNCSEの他に、既存の2つの尺度についても調査が行われました。
- Q1~Q15:理科における認知欲求尺度(NCSE)
- Q16~Q27:知的好奇心尺度(西川・雨宮, 2015)
- Q28~Q50:批判的思考尺度(木下・山中, 2014)
調査で取得した回答データは、以下のOSFサイトに公開されています。
osf.io
データの読み込み
csvファイルを読み込んで、分析に使用するデータを取り出します。
#データの読み込み library(readr) dat1 <- read_csv("SNFC_7.csv") View(dat1) #データ抽出 dat2 <- subset(dat1,select=c("Q1","Q2","Q3","Q4","Q6","Q7","Q8","Q9","Q10","Q11","Q12","Q13","Q14","Q15")) dat2 <- na.omit(dat2) #欠損値を除去
項目反応理論の前提の確認
項目反応理論(IRT)では適用の前提条件として、項目群の一次元性(unidimensionality) 局所独立性(local independence) 潜在単調性(latent monotonicity)が求められます(豊田,2013 ; Yang & Kao, 2014)。そこで、IRTに基づく分析の前に、これらの前提条件を確認していきます。
一次元性
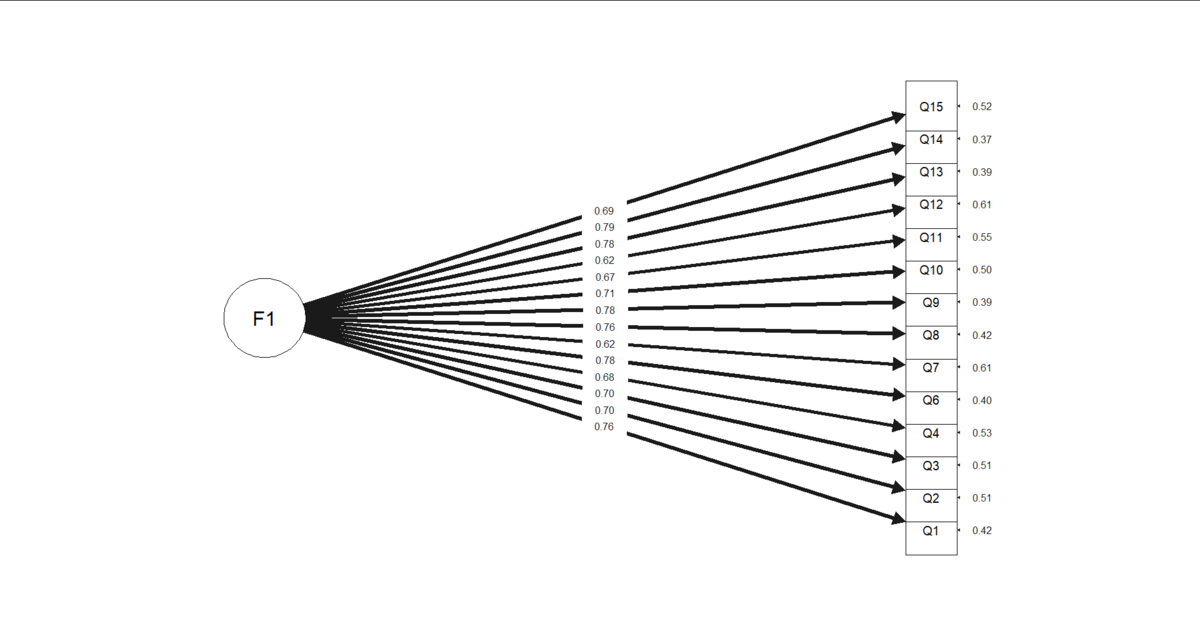
確認的因子分析(CFA: Confirmatory Factor Analysis)を行った結果、適合度は CFI=.924, TLI=.910, RMSEA=.090, SRMR=.042 で、認知欲求に関する先行研究と同様に1因子構造が支持されました。これらの結果から、項目群の一次元性を確認しました。
#確認的因子分析(CFA)##### #ポリコリック相関 library(psych) polychoric(dat2) #SEM library(lavaan) #1因子モデル(remove:Q5) model <- " F1=~Q1+Q2+Q3+Q4+Q6+Q7+Q8+Q9+Q10+Q11+Q12+Q13+Q14+Q15 " fit1 <- cfa(model,data=dat2,ordered=colnames(dat2), std.lv=TRUE) summary(fit1,standardized = T, fit.measures = T) modificationIndices(fit1, minimum.value = 100) #修正指標 #信頼性係数 psych::alpha(dat2) #α係数 omega(nfactors = 1, dat2) #ω係数 群因子数=1 #SEM図のプロット library(semPlot) semPaths(fit1, "std", rotation = 2, edge.label.cex = 1.0, style="lisrel", fade=F, theme='gray', label.cex=1.7)
局所独立性
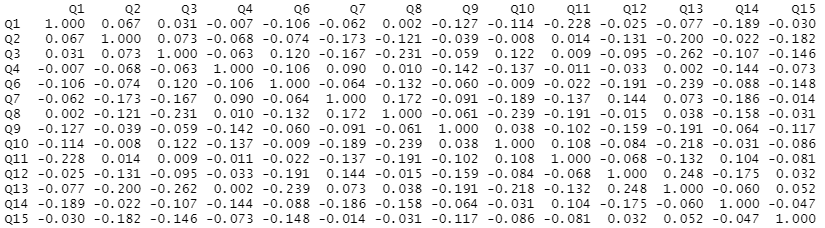
局所独立性の指標としては、YenのQ3統計量(Yen’s Q3 statistic)を算出しました。YenのQ3統計量は、カテゴリカル因子分析の残差間の相関で、絶対値が0.36以下であれば局所独立の仮定が満たされていると判断できます(Smits et al., 2012)。YenのQ3統計量が-0.262―0.248であったことから、項目群の局所独立性を確認しました。
#局所独立の検討 library(mirt) x <- mirt(dat2, 1) residuals(x) Theta <- fscores(x) round(residuals(x, type = 'Q3', Theta=Theta),2)
潜在単調性
潜在単調とは、項目が構成概念と単調性を満たす関係にあり、各反応カテゴリーが固有の区間で最大の選択確率を持つ状態のことを指します。つまり、特性値の高い人が低い人に比べて、より上位の選択肢を選ぶ状態が成立している状態です。ここでは、ノンパラメトリックIRTの1モデルであるモッケン尺度分析(MSA: Mokken Scale Analysis)によって、顕在単調性を利用した潜在単調性の確認を行います。MSAの結果において、H係数が大きいほど顕在単調であることを表しています。H係数の値は、0.30以上で「弱い」、0.40以上で「中程度」、0.50以上で「強い」と解釈できます(Mokken, 1997)。
library(mokken) dat3 <- dat2-1 #顕在単調性を用いた潜在単調性の確認. 豊田(2013)11章参照. mono.list<-check.monotonicity(dat3) summary(mono.list)
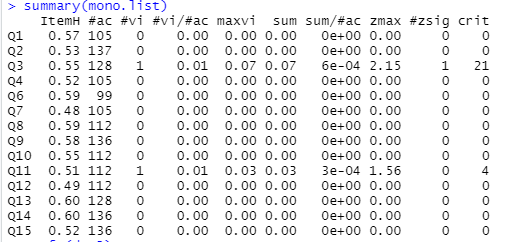
H係数の結果から、潜在単調性を確認しました。
項目反応理論に基づく推定
検討するモデル
尺度構成を検討するために,多値型の項目反応理論の代表的なモデルである段階反応モデル(GRM: Graded Response Model; Samejima, 1969)と一般化部分採点モデル(GPCM: Generalized Partial Credit Model; Muraki, 1997)の適用を検討します。
GRMにおいてある選択番号を選ぶ確率は式(1)で定義されます。式中のは個人特性値、
は識別力、
は困難度を表すパラメータです。添え字の
は個人、
は項目、
は選択された番号(0―4)を表します。ただし、
は
以上の選択肢を選ぶ確率であり、
,
とします。
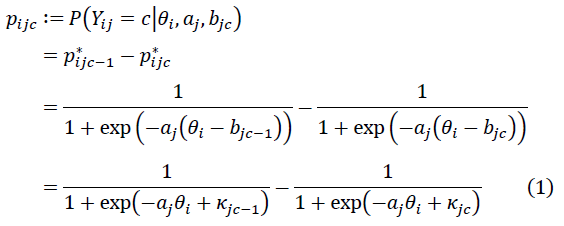
他方、GPCMにおいてある選択番号を選ぶ確率は式(2)で定義されます。式中のは個人特性値、
は識別力、
はカテゴリー境界を表すパラメータです。添え字の
は個人、
は項目、
は選択された番号(0―4)、Cは選択肢のカテゴリー数(今回はC = 5)、
はカテゴリー境界番号を表します。ただし、
とします。
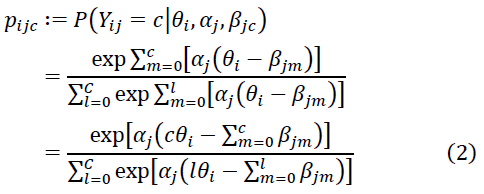
今回使用する2つのモデルの違いの1つは、選択肢に対する反応プロセスの想定にあります。GPCMでは、ある選択肢c に反応するか否かが、隣接する選択肢c − 1 との比較から決定されると仮定しているのに対して、GRMでは、各選択肢に対する絶対的な基準が存在することが仮定されています(宇都・植野,2018)。
2つのモデルをベイズ推定する際の確率モデルと事前分布をプレート表現(plate notation)で整理します。(※プレート表現はよく分かっていないので、間違っていたらごめんなさい。)
GRMのプレート表現は下図の通りです。事前分布はLuo & Jiao(2017)を参考にしました。図では、ある人物がある項目
に対して選択肢
を選ぶ確率
は、困難度パラメータ
、識別力パラメータ
、特性値パラメータ
によって決定することを示しています。

GPCMのプレート表現は下図の通りです。事前分布は清水(2018)を参考にしました。図では、ある人物がある項目
に対して選択肢cを選ぶ確率
は、カテゴリー境界パラメータ
、識別力パラメータ
、特性値パラメータ
によって決定することを示しています。

次に、stanでMCMCを回して2つのモデルのパラメータを推定します。
GRMのベイズ推定
GRMのstanコードは、7日目の項目反応理論の記事でも紹介のあったLuo & Jiao(2017)のコードを利用します。項目パラメータと個人特性値を同時推定します。kappaをalphaで除したものが式(1)の困難度パラメータbに相当します。
#GRM#####
#Luo & Jiao(2017)より引用
grm <-'
data{
int<lower=2, upper=5> K; //number of categories
int <lower=0> n_student;
int <lower=0> n_item;
int<lower=1,upper=K> Y[n_student,n_item];
}
parameters {
vector[n_student] theta;
real<lower=0> alpha [n_item];
ordered[K-1] kappa[n_item]; //category difficulty
real mu_kappa; //mean of the prior distribution of category difficulty
real<lower=0> sigma_kappa; //sd of the prior distribution of category difficulty
}
model{
alpha ~ cauchy(0,5);
theta ~ normal(0,1);
for (i in 1: n_item){
for (k in 1:(K-1)){
kappa[i,k] ~ normal(mu_kappa,sigma_kappa);
}}
mu_kappa ~ normal(0,5);
sigma_kappa ~ cauchy(0,5);
for (i in 1:n_student){
for (j in 1:n_item){
Y[i,j] ~ ordered_logistic(theta[i]*alpha[j],kappa[j]);
}}
}
generated quantities {
vector[n_item] log_lik[n_student];
for (i in 1: n_student){
for (j in 1: n_item){
log_lik[i, j] = ordered_logistic_log (Y[i, j],theta[i]*alpha[j],kappa[j]);
}}
}
'Rコードは以下の通りです。結果が出るまで1時間くらいかかるかもしれません。
#使用データ Y <- dat2 n_student <- nrow(Y) n_item <- 14 K <- 5 data_ori <- list(Y=Y, n_item=n_item, n_student=n_student, K=K) #ベイズ推定 library(rstan) rstan_options(auto_write = TRUE) options(mc.cores = parallel::detectCores()) fit_grm <- stan(model_code = grm, data=data_ori, seed=1234, chains=4, warmup=1000, iter=2000) #出力保存 sink("./resultgrm.txt") print(fit_grm, digits_summary=3) sink() #rhat stan_rhat(fit_grm) #WAIC library(loo) tmp01 <- extract_log_lik(fit_grm) waic_grm <- waic(tmp01) print(waic_grm , digits = 3)
各個人の特性値θと項目パラメータの推定値が出力されています。

Rhatも問題なさそう。
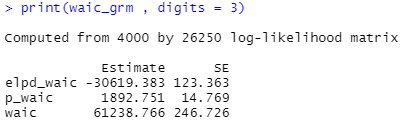
looパッケージで求めたWAICはこんな感じ(間違っている可能性あり)
GPCMのベイズ推定
GRMのstanコードは、清水(2018)を一部改変して利用します。
#清水(2018)より一部改変
gpcm <- "
data{
int N;
int P;
int S;
int Y[N,P];
}
transformed data{
vector[S] c = cumulative_sum(rep_vector(1,S))-1;
}
parameters{
vector<lower=0>[P] alpha;
vector[S-1] beta[P];
vector[N] theta;
}
transformed parameters{
vector[S] thr[P];
for(p in 1:P){
thr[p] = cumulative_sum(append_row(0,beta[p]));
}
}
model{
//model
for (n in 1:N){
for(p in 1:P){
Y[n,p] ~ categorical_logit(alpha[p]*(c*theta[n]-thr[p]));
}
}
//prior
theta ~ normal(0,1);
alpha ~ cauchy(0,5); //変更箇所
for(s in 1:S) beta[s] ~ normal(0,10);
}
generated quantities{
vector[N] log_lik = rep_vector(0,N);
for (n in 1:N){
for(p in 1:P){
log_lik[n] += categorical_logit_lpmf(Y[n,p] | alpha[p]*(c*theta[n]-thr[p]));
}
}
}
"
Rコードは以下の通りです。結果が出るまで1時間くらいかかるかもしれません。
#使用データ Y <- dat2 N <- nrow(Y) P <- 14 S <- 5 data_gpcm <- list(Y=Y,N=N,S=S,P=P) #ベイズ推定 fit_gpcm <- stan(model_code = gpcm, data=data_gpcm, seed=1234, chains=4, warmup=1000, iter=2000) #出力保存 sink("./resultgpcm.txt") print(fit_gpcm, digits_summary=3) sink() #rhat stan_rhat(fit_gpcm) #WAIC library(loo) tmp02 <- extract_log_lik(fit_gpcm) waic_gpcm <- waic(tmp02) print(waic_gpcm, digits = 4)
各個人の特性値θと項目パラメータの推定値が出力されています。
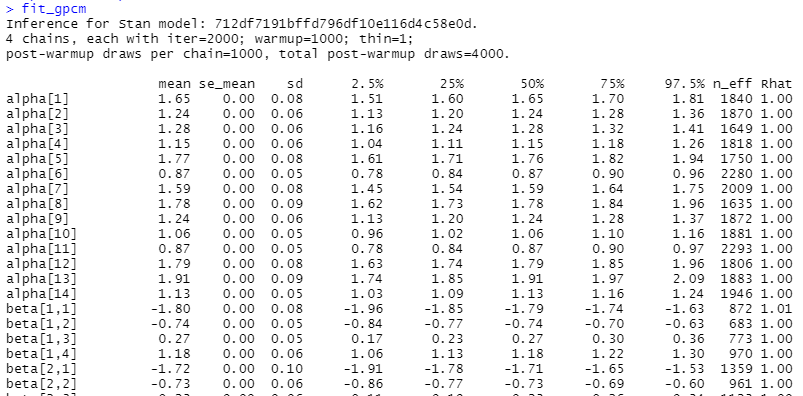
Rhatも問題なさそう。
looパッケージで求めたWAICはこんな感じ(間違っている可能性あり)
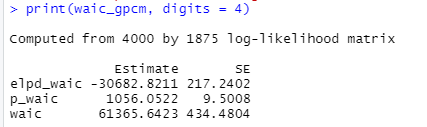
looパッケージで求めたWAICは間違っている可能性があるのは承知の上で、ここでは深入りせず、値が相対的に小さかったGRMモデルを採択することにします。
項目パラメータと特性値θ
GRMモデルに基づく項目困難度(b)と識別力(a)の推定値は下の表の通りです。Q13「自然現象のきまりを考えることが好きである。」といった項目は困難度が相対的に高いようです。Q12「ふしぎな自然現象に出会うとワクワクする。」といった項目は困難度が相対的に低いようです。
| Q | b1 | b2 | b3 | b4 | a |
|---|---|---|---|---|---|
| 1 | -1.85485 | -0.72772 | 0.266494 | 1.249245 | 2.434515 |
| 2 | -1.82368 | -0.70748 | 0.271375 | 1.328595 | 2.049436 |
| 3 | -2.27505 | -1.25213 | -0.33051 | 0.714960 | 2.025606 |
| 4 | -1.68445 | -0.62644 | 0.455219 | 1.548115 | 1.886240 |
| 6 | -1.82689 | -0.82793 | 0.109689 | 1.001456 | 2.622845 |
| 7 | -1.92745 | -0.79416 | 0.121554 | 1.187151 | 1.617514 |
| 8 | -1.24906 | -0.31887 | 0.591786 | 1.356222 | 2.506673 |
| 9 | -1.51955 | -0.60269 | 0.334477 | 1.176411 | 2.727634 |
| 10 | -1.95468 | -0.94478 | -0.01237 | 0.831938 | 2.095990 |
| 11 | -1.81203 | -0.85462 | 0.220705 | 1.287459 | 1.860610 |
| 12 | -2.15309 | -1.27225 | -0.41793 | 0.590034 | 1.650233 |
| 13 | -1.46675 | -0.58102 | 0.435049 | 1.255665 | 2.696348 |
| 14 | -1.39102 | -0.49256 | 0.499843 | 1.387721 | 2.839639 |
| 15 | -1.63837 | -0.69932 | 0.229261 | 1.075459 | 2.003322 |
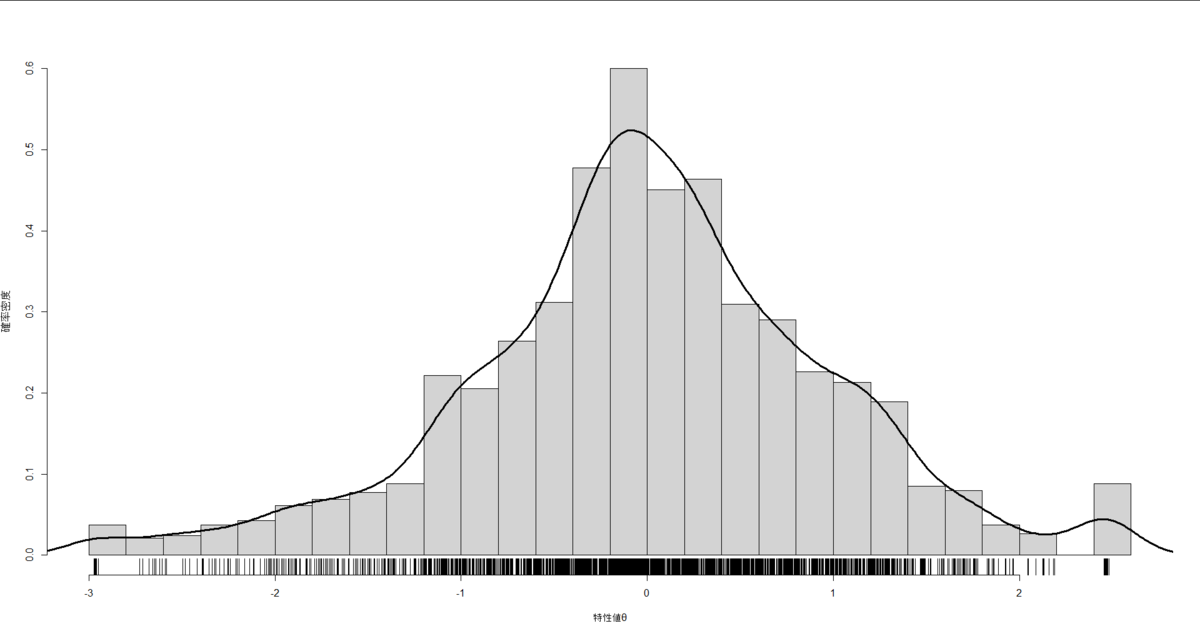
特性値θの分布はこんな感じの標準正規分布に近い形。
余談ですが、将来的にこの尺度が学校現場で活用されることも期待して、回答データから特性値θをEAP推定するShinyアプリも作ってみました。
理科における認知欲求尺度の推定アプリケーション
性差の検討
次に、今回得られたサンプルが母集団を代表するものであるという仮定の下、母集団におけるNCSEの性差について検討します。
認知欲求の性差についてPreckel(2014)は、小学校第5学年の初期には男性の方が認知欲求が高いものの、学年進行とともに性差が減少することを報告しています、Grass et al.(2017)は大学生を対象とした調査を通して認知欲求は男性の方がわずかに高い傾向にあることを示しています。日本の子供のデータでも男性の方が高い傾向にあるのでしょうか?ここでは、特性値θを所与のものとして、性差の程度を検討していきます。
検討するモデル
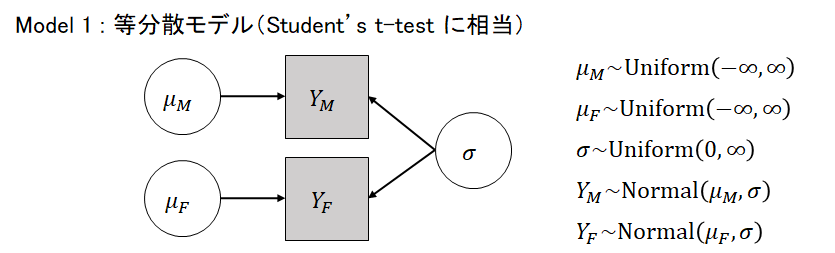
男性と女性という2群の母平均の差について検討するために、Studentのt検定(等分散モデル)とWelchのt検定(異分散モデル)に相当する2つのモデルを検討します。まず、2つのモデルをベイズ推定する際の確率モデルと事前分布をプレート表現(plate notation)で整理します。
等分散モデルのプレート表現は下図の通りです。σが共通分散です。
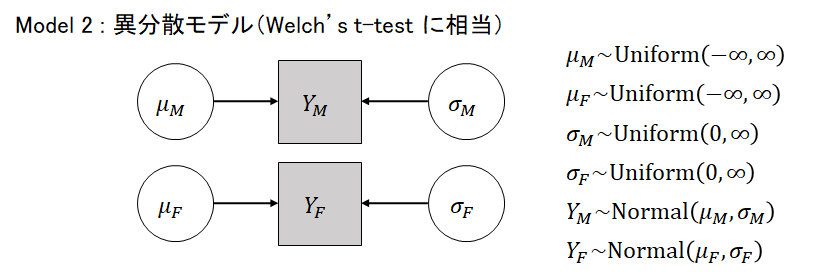
異分散モデルのプレート表現は下図の通りです。それぞれにσが設定されています。
データの読み込み
GRMモデルで推定した特性値θが格納されたcsvファイルを読み込みます。
このcsvファイルもOSFに上げてあります。
osf.io
#使用データ library(readr) dat4 <- read_csv("data_extract.csv") x <- subset(dat4$theta, dat4$sex==2) #第1群の指定 Female y <- subset(dat4$theta, dat4$sex==1) #第2群の指定 Male nx <- length(x) ny <- length(y) gender <- list(N1=nx, N2=ny, x1=x, x2=y, c=0)
等分散モデルのベイズ推定
stanコードはこんな感じでしょうか。
#等分散(正規分布)
equ <- '
data{
int<lower=0> N1;
int<lower=0> N2;
real x1[N1];
real x2[N2];
real c;
}
parameters{
real mu1; //Female
real mu2; //Man
real<lower=0> sigma;
}
model{
x1 ~ normal(mu1,sigma); //Female
x2 ~ normal(mu2,sigma); //Man
}
generated quantities{
real delta;
real d_overC;
real cohen_d;
real mu1_new;
real mu2_new;
real log_lik;
delta = mu2 - mu1;
d_overC = (delta>c? 1:0);
cohen_d = delta /((sigma^2*(N1-1)+sigma^2*(N2-1)) /((N1-1)+(N2-1)))^0.5;
mu1_new = normal_rng(mu1,sigma);
mu2_new = normal_rng(mu2,sigma);
log_lik =normal_lpdf(x1 | mu1,sigma)+
normal_lpdf(x2 | mu2,sigma); //対数尤度
}
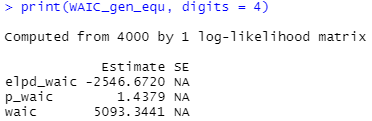
'Rコードは以下の通りです。
#ベイズ推定 fit_gen_equ <- stan(model_code=equ, data=gender, chains=4, warmup=1000, iter=2000) print(fit_gen_equ, digits_summary=3) #出力保存 sink("./gender_equ.txt") print(fit_gen_equ,digits_summary=3) sink() #WAIC library(loo) tmp_gen_equ <- extract_log_lik(fit_gen_equ) WAIC_gen_equ <- waic(tmp_gen_equ) print(WAIC_gen_equ, digits = 4)
結果はこんな感じです。

異分散モデルのベイズ推定
stanコードはこんな感じでしょうか。
#異分散(正規分布)
diff <- '
data{
int<lower=0> N1;
int<lower=0> N2;
real x1[N1];
real x2[N2];
real c;
}
parameters{
real mu1; //Female
real mu2; //Man
real<lower=0> sigma1;
real<lower=0> sigma2;
}
model{
x1 ~ normal(mu1,sigma1); //Female
x2 ~ normal(mu2,sigma2); //Man
}
generated quantities{
real delta;
real d_overC;
real cohen_d;
real mu1_new;
real mu2_new;
real log_lik;
delta = mu2 - mu1;
d_overC = (delta>c? 1:0);
cohen_d = delta /((sigma1^2*(N1-1)+sigma2^2*(N2-1)) /((N1-1)+(N2-1)))^0.5;
mu1_new = normal_rng(mu1,sigma1);
mu2_new = normal_rng(mu2,sigma2);
log_lik =normal_lpdf(x1 | mu1,sigma1)+
normal_lpdf(x2 | mu2,sigma2); //対数尤度
}
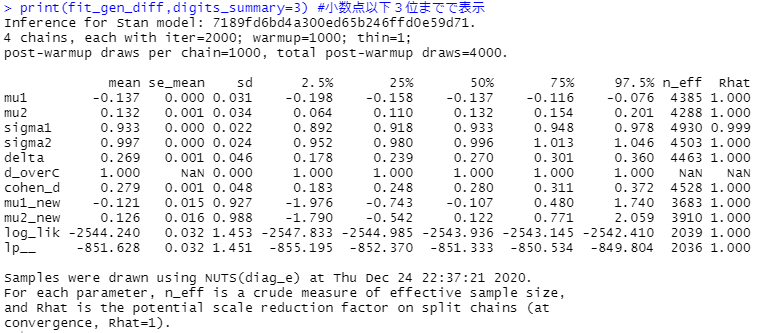
'Rコードは以下の通りです。
#ベイズ推定 fit_gen_diff=stan(model_code=diff,data=gender,chains=4,warmup=1000,iter=2000) #(2000-1000)*4の乱数を発生させる print(fit_gen_diff,digits_summary=3) #小数点以下3位までで表示 #出力保存 sink("./gender_diff.txt") print(fit_gen_diff,digits_summary=3) sink() #WAIC library(loo) tmp_gen_diff <- extract_log_lik(fit_gen_diff) WAIC_gen_diff <- waic(tmp_gen_diff) print(WAIC_gen_diff, digits = 4)
結果はこんな感じです。
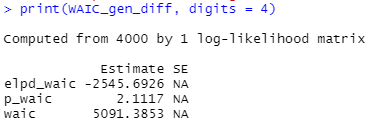
WAICの値だけ見ると異分散モデルの方が良さそうです。
先行研究と同様、NCSEは男性の方が高い傾向にありそうです(d=0.28)。
まとめ
この記事では、GRMとGPCMをstanで実行した具体例を紹介しました。また、t検定に相当するモデルを通して性差を検討する例を紹介しました。雑な紹介記事になってしまい申し訳ありませんが少しでも参考になれば幸いです。統計については初心者で記事の内容に誤りがある可能性があるので、お気づきの方はぜひコメントいただければ幸いです。事例で紹介した理科における認知欲求尺度についてはこちらのOSFサイトをご覧ください。
OSF | 理科における認知欲求尺度の構成 Wiki
追記1:サンプルサイズ設計
今回は扱いませんでしたが、ベイズファクターを用いた仮説検定を計画していた場合、事前にサンプルサイズ設計を行うことも考えられます。例えば、本記事で扱った性差の検討でベイズファクターを用いた検定を行う場合、事前のサンプルサイズ設計は以下のコードで検討できます。検定力は0.8、発生させる乱数の数は10000としています。また、異分散モデルでは先行研究を参考に異なる分散の値を仮定しています。SSDbainパッケージの詳細についてはFu, Hoijtink, & Moerbeek (2020) をご覧ください。
library(devtools) install_github("Qianrao-Fu/SSDbain",upgrade="never") library(SSDbain) #等分散モデル SSDttest(type='equal', Population_mean=c(0.2,0), var=NULL, BFthresh=10, eta=0.80, Hypothesis ='two-sided', T=10000) #異分散モデル SSDttest(type='unequal', Population_mean=c(0.2,0), var=c(0.932,0.997), BFthresh=10, eta=0.80, Hypothesis ='two-sided', T=10000)
例えば、等分散モデルの結果はこんな感じです。
は帰無仮説が真である場合に
が10を超える確率、
は対立仮説が真である場合に
が10を超える確率です。
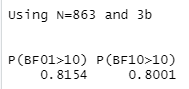
各群n=863あれば検定力0.8を達成できそうだと見積もれます。
追記2:局所独立性の検討
記事公開後、Twitter上でベイズ推定後の結果を利用して局所独立性を検討した方が良いのではないかという意見をいただきました。
Smits et al. (2012)では相関係数の効果量の考え方から,Q3の目安を導いていますので,同じ方法で計算するQ3の目安は研究によって変わるべきだと思います。別の研究では.2を超えたら要注意とも言われますし。
— しぶてぃ (@takuizum) 2021年1月1日
A~Bの間の値ならOKという,根拠の薄い断言の仕方はまずい https://t.co/QoSuLpZ9Ek
結局,局所依存の程度はIRTのモデルフィット後に調べるしかないので,Stanでベイズ推定した結果を利用したほうが望ましいのではないだろうか。もっと言えば,ベイズ的に局所依存の程度を定量化できる指標などはないのだろうか。
— しぶてぃ (@takuizum) 2021年1月1日
そこで、簡易的な分析として、GRMモデルの項目パラメータのEAP推定値を利用して、Q3統計量を計算してみます。
流れとしては、まず、関数を定義した上で各カテゴリへの反応確率を計算し、期待項目得点を求めます。そして、残差(期待項目得点と実際の項目反応の差)と残差間の相関(Q3統計量)を計算します。コードは以下の通りです。上手い書き方が思いつかなかったので汚いコードになっています。
#使用データ library(readr) dat3 <- read_csv("data_extract.csv") #GRMの関数定義 grmprob1 <- function(a, b1, theta){ 1-(1/(1+exp(-a*(theta-b1)))) } grmprob2 <- function(a, b1, b2, theta){ (1/(1+exp(-a*(theta-b1))))-(1/(1+exp(-a*(theta-b2)))) } grmprob3 <- function(a, b2, b3, theta){ (1/(1+exp(-a*(theta-b2))))-(1/(1+exp(-a*(theta-b3)))) } grmprob4 <- function(a, b3, b4, theta){ (1/(1+exp(-a*(theta-b3))))-(1/(1+exp(-a*(theta-b4)))) } grmprob5 <- function(a, b4, theta){ (1/(1+exp(-a*(theta-b4))))-0 } #項目反応確率 #Q1 dat3$expQ1_1 <- grmprob1(a=2.434515, b1=-1.85485, theta = dat3$theta) dat3$expQ1_2 <- grmprob2(a=2.434515, b1=-1.85485, b2=-0.72772, theta = dat3$theta) dat3$expQ1_3 <- grmprob3(a=2.434515, b2=-0.72772, b3=0.266494, theta = dat3$theta) dat3$expQ1_4 <- grmprob4(a=2.434515, b3=0.266494, b4=1.249245, theta = dat3$theta) dat3$expQ1_5 <- grmprob5(a=2.434515, b4=1.249245, theta = dat3$theta) #Q2 dat3$expQ2_1 <- grmprob1(a=2.049436, b1=-1.82368, theta = dat3$theta) dat3$expQ2_2 <- grmprob2(a=2.049436, b1=-1.82368, b2=-0.70748, theta = dat3$theta) dat3$expQ2_3 <- grmprob3(a=2.049436, b2=-0.70748, b3=0.271375, theta = dat3$theta) dat3$expQ2_4 <- grmprob4(a=2.049436, b3=0.271375, b4=1.328595, theta = dat3$theta) dat3$expQ2_5 <- grmprob5(a=2.049436, b4=1.328595, theta = dat3$theta) #Q3 dat3$expQ3_1 <- grmprob1(a=2.025606, b1=-2.27505, theta = dat3$theta) dat3$expQ3_2 <- grmprob2(a=2.025606, b1=-2.27505, b2=-1.25213, theta = dat3$theta) dat3$expQ3_3 <- grmprob3(a=2.025606, b2=-1.25213, b3=-0.33051, theta = dat3$theta) dat3$expQ3_4 <- grmprob4(a=2.025606, b3=-0.33051, b4=0.714960, theta = dat3$theta) dat3$expQ3_5 <- grmprob5(a=2.025606, b4=0.714960, theta = dat3$theta) ####以下Q15まで繰り返し。(中略)#### #期待項目得点 dat3$expQ1c <- apply(dat3[,60:64], MARGIN = 1, which.max) dat3$expQ2c <- apply(dat3[,65:69], MARGIN = 1, which.max) dat3$expQ3c <- apply(dat3[,70:74], MARGIN = 1, which.max) dat3$expQ4c <- apply(dat3[,75:79], MARGIN = 1, which.max) dat3$expQ6c <- apply(dat3[,80:84], MARGIN = 1, which.max) dat3$expQ7c <- apply(dat3[,85:89], MARGIN = 1, which.max) dat3$expQ8c <- apply(dat3[,90:94], MARGIN = 1, which.max) dat3$expQ9c <- apply(dat3[,95:99], MARGIN = 1, which.max) dat3$expQ10c <- apply(dat3[,100:104], MARGIN = 1, which.max) dat3$expQ11c <- apply(dat3[,105:109], MARGIN = 1, which.max) dat3$expQ12c <- apply(dat3[,110:114], MARGIN = 1, which.max) dat3$expQ13c <- apply(dat3[,115:119], MARGIN = 1, which.max) dat3$expQ14c <- apply(dat3[,120:124], MARGIN = 1, which.max) dat3$expQ15c <- apply(dat3[,125:129], MARGIN = 1, which.max) #残差 dat3$res1 <- dat3$Q1-dat3$expQ1c dat3$res2 <- dat3$Q2-dat3$expQ2c dat3$res3 <- dat3$Q3-dat3$expQ3c dat3$res4 <- dat3$Q4-dat3$expQ4c dat3$res6 <- dat3$Q6-dat3$expQ6c dat3$res7 <- dat3$Q7-dat3$expQ7c dat3$res8 <- dat3$Q8-dat3$expQ8c dat3$res9 <- dat3$Q9-dat3$expQ9c dat3$res10 <- dat3$Q10-dat3$expQ10c dat3$res11 <- dat3$Q11-dat3$expQ11c dat3$res12 <- dat3$Q12-dat3$expQ12c dat3$res13 <- dat3$Q13-dat3$expQ13c dat3$res14 <- dat3$Q14-dat3$expQ14c dat3$res15 <- dat3$Q15-dat3$expQ15c #Q3統計量(残差間の相関) Q3 <- cor(dat3[,144:157]) round(Q3, 3)
結果は、以下の通り。Q6とQ13、Q12とQ13で絶対値0.2をやや超えていた。

Reference
- Baker, F. B. (2001): The Basics of Item Response Theory (2nd. ed., pp. 42–44). MD: ERIC Clearinghouse on Assessment and Evaluation.
- Cacioppo, J. T., & Petty, R. E. (1982): The need for cognition. Journal of Personality and Social Psychology, 42(1), 116–131. https://doi.org/10.1037/0022-3514.42.1.116
- Cacioppo, J. T., Petty, R. E., Feinstein, J. A., Blair, W., & Jarvis, G. (1996): Dispositional differences in cognitive motivation: The life and times of individuals varying in need for cognition. Psychological Bulletin, 119(2), 197–253. https://doi.org/10.1037/0033-2909.119.2.197
- Cacioppo, J. T., Petty, R. E., Kao, C. F., & Rodriguez, R. (1986): Central and peripheral routes to persuasion: An individual difference perspective. Journal of Personality and Social Psychology, 51(5), 1032–1043. https://doi.org/10.1037/0022-3514.51.5.1032
- Fu, Q., Hoijtink, H., & Moerbeek, M. (2020). Sample-size determination for the Bayesian t test and Welch's test using the approximate adjusted fractional Bayes factor. Behavior research methods. https://doi.org/10.3758/s13428-020-01408-1
- Grass, J., Strobel, A., & Strobel, A. (2017): Cognitive Investments in Academic Success: The Role of Need for Cognition at University. Frontiers in Psychology. 8(790). https://doi.org/10.3389/fpsyg.2017.00790
- 平山るみ・楠見孝 (2004): 批判的思考態度が結論導出プロセスに及ぼす影響―証拠評価と結論生成課題を用いての検討, 教育心理学研究, 52(2), 186–198. https://doi.org/10.5926/jjep1953.52.2_186
- Junker, B. W. & Sijtsma, K. (2000): Latent and manifest monotonicity in item response models. Applied Psychological Measurement, 24, 65–81. https://doi.org/10.1177/01466216000241004
- 木下博義・山中真悟 (2014): 理科学習における中学生の批判的思考に関する調査研究, 広島大学大学院教育学研究科紀要 第二部 文化教育開発関連領域, 63, 15–21. http://doi.org/10.15027/36628
- 神山貴弥・藤原武弘 (1991): 認知欲求尺度に関する基礎的研究, 社会心理学研究, 6(3), 184–192. https://doi.org/10.14966/jssp.KJ00003725148
- Luo, Y. (2018): Parameter recovery with marginal maximum likelihood and markov chain monte carlo estimation for the generalized partial credit model. arXiv preprint arXiv:1809.07359
- Luo, Y., & Jiao, H. (2018): Using the Stan program for Bayesian item response theory. Educational and psychological measurement, 78(3), 384–408. https://doi.org/10.1177/0013164417693666
- Mokken, R. J. (1997): Nonparametric models for dichotomous responses. In van der Linden, W. J. & Hambleton, R. K. (Eds.), Handbook of modern item response theory (pp. 351–367). New York: Springer.
- Muraki, E. (1997): A generalized partial credit model. In W. J. van der Linden & R. K. Hambleton (Eds.), Handbook of modern item response theory (pp. 153–164). New York: Springer.
- 西川一二・雨宮俊彦 (2015): 知的好奇心尺度の作成―拡散的好奇心と特殊的好奇心, 教育心理学研究, 63(4), 412–425. https://doi.org/10.5926/jjep.63.412
- Petty, R. E., & Cacioppo, J. T. (1981): Attitudes and persuasion: Classic and contemporary approaches. Dubuque, IA: William. C. Brown.
- Preckel, F. (2014). Assessing need for cognition in early adolescence: Validation of a German adaption of the Cacioppo/Petty Scale. European Journal of Psychological Assessment, 30(1), 65–72. https://doi.org/10.1027/1015-5759/a000170
- Samejima, F. (1969): Estimation of latent ability using a response pattern of graded scores. Psychometrika Monograph Supplement, 34, 1–97. https://doi.org/10.1007/BF03372160
- 清水裕士 (2018): 俺流 MCMCの結果の見方コード. Retrieved from https://norimune.net/3138 (2020年3月7日)
- Smits, N., Zitman, F. G., Cuijpers, P., den Hollander-Gijsman, M. E., & Carlier, I. V. (2012). A proof of principle for using adaptive testing in Routine Outcome Monitoring: the efficiency of the Mood and Anxiety Symptoms Questionnaire -Anhedonic Depression CAT. BMC medical research methodology, 12, 4. https://doi.org/10.1186/1471-2288-12-4
- Strobel, A., Behnke, A., Gärtner, A., & Strobel, A. (2019): The interplay of intelligence and need for cognition in predicting school grades: A retrospective study. Personality and Individual Differences, 144, 147–152. https://doi.org/10.1016/j.paid.2019.02.041
- 豊田秀樹 (2013): 項目反応理論[中級編], 朝倉書店.
- 雲財寛・中村大輝 (2018): 理科における認知欲求尺度の開発, 科学教育研究,42(4), 301–313. https://doi.org/10.14935/jssej.42.301
- 宇都雅輝・植野真臣 (2018): ピアアセスメントにおける異質評価者に頑健な項目反応理論, 電子情報通信学会論文誌 D, 101(1), 211–224. https://doi.org/10.14923/transinfj.2017JDP7055
- Yang, F. M., & Kao, S. T. (2014): Item response theory for measurement validity. Shanghai Archives of Psychiatry, 26(3), 171–177.